Cluster Restores
The Cluster/Restores page shows all configured restore job definitions, and allows you to run them, edit them, delete them, or create new ones. Restore definitions are retained so that they can be modified and/or re-run later if desired. You can simply delete any old restore definitions that you don’t wish to save.
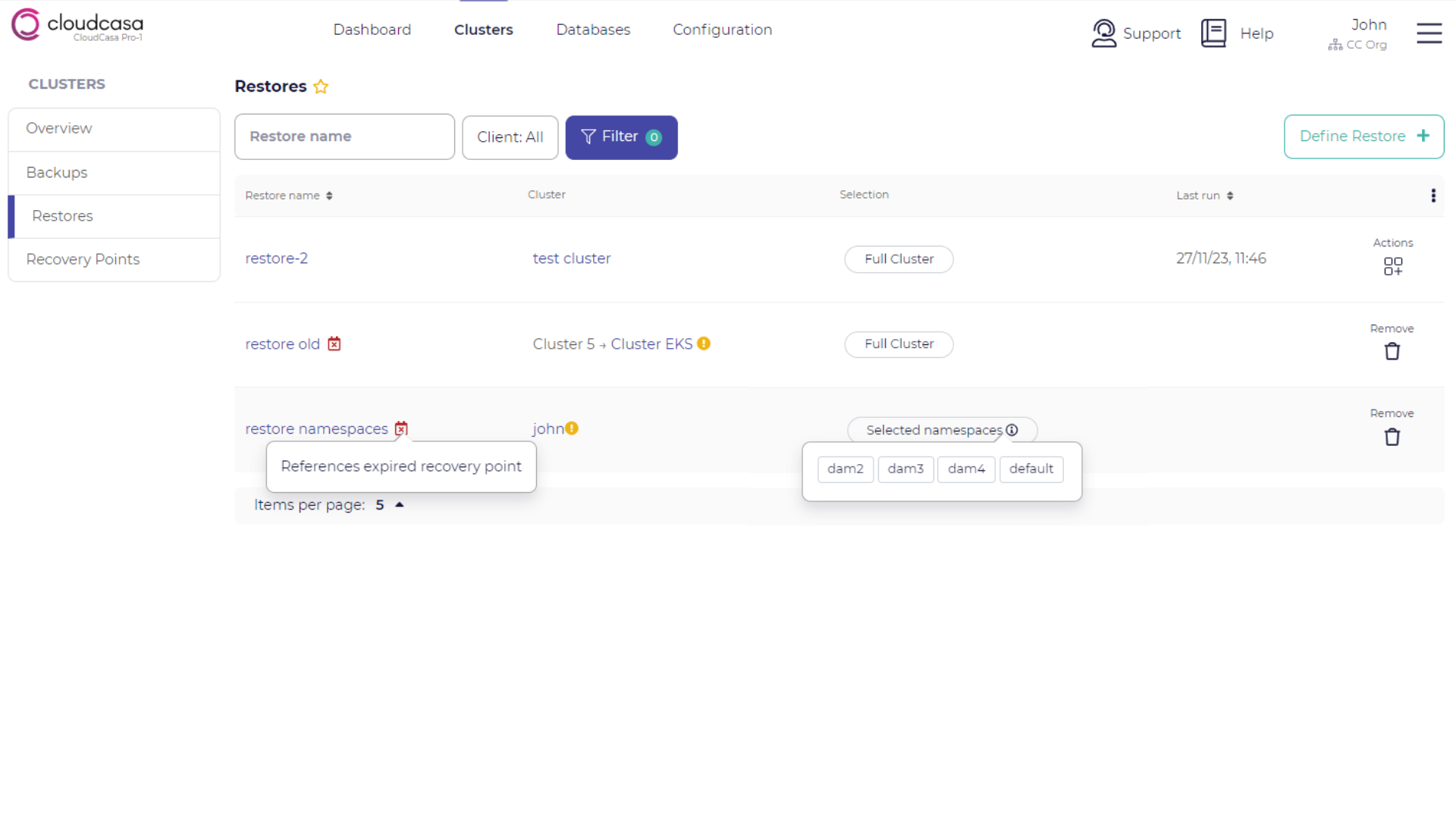
The columns displayed in the table are: Restore job name, cluster, Selection, and Last run time. The selection column gives a brief indication of what is selected for restore in the definition, such as “Selected namespaces” or “Specific resources”. An (i) or (!) icon indicates that additional information is available by mousing over it. One or more action buttons may also be available for each restore job definition.
Possible actions are:
- Remove
Delete the restore job.
- Run now
Run the restore job immediately.
- Edit
Edit the restore job definition.
Jobs which are defined on a recovery point that is no longer available cannot be run or edited. They can only be deleted.
Clicking on a restore job name in the table will take you to the job’s dashboard, which displays summary and activity information about the job.
To define a new restore job, click the Define Restore button in the upper right of the page. This will open the Cluster Restore Wizard.
See also
For more information on defining a restore job, see the Cluster Restore Wizard.